𝗪𝗵𝘆 𝗶𝘀 𝗠𝗮𝗽 𝗡𝗼𝘁 𝗜𝘁𝗲𝗿𝗮𝗯𝗹𝗲 𝗶𝗻 𝗝𝗮𝘃𝗮?— Most Asked Interv
“Why is Map not directly Iterable in Java?”
blog.stackademic.com
왜 Map은 반복 가능하지 않은가?
이 글에서는 Map의 반복 가능하지 않도록 설계된 이유에 대해서 말합니다.
이를 확장해 class, interface 상속에 대한 내용도 추가해 놓았습니다.
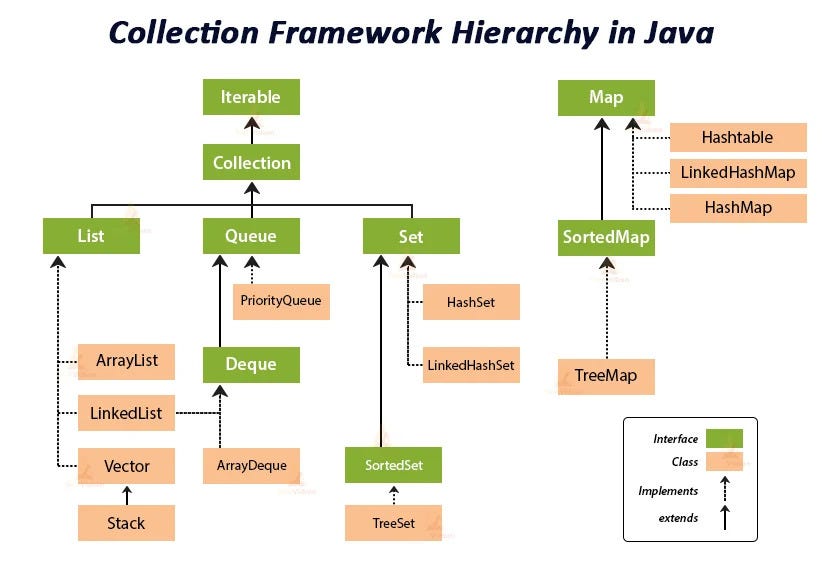
Java Collection 프레임워크의 구조를 보면 알 수 있듯이, Map은 Collection이 아니며 Iterable 또한 상속받지 않습니다.
(Iterable 을 상속의 의미는 Enhanced For Loop 를 사용할 수 있음을 말합니다)
위의 글에서는 왜 "Map은 Iterable 하지 않은가?" 에 대해 말합니다.
주된 주장은 Map은 Collection, 즉 요소의 집합이 아니며 Pair의 묶음이라는 것 입니다.Map은 기본적으로 key-value 형태의 쌍이기 때문에, 명시하지 않는다면 어떤 원소값의 반복인지 알 수 없습니다.
- key 값을 반복
- value를 반복
- key-value 쌍을 반복
이렇게 다양한 옵션들이 있기 때문에 정확히 무엇을 순회할건지를 알 수 없는 모호함이 발생한다는 것으로
정확히 어떤것을 순회할지를 나타낸 후에야 Iterable해지는 것을 알 수 있습니다.
Map<String, Integer> scores = new HashMap<>();
scores.put("Madhavi", 90);
scores.put("Kiran", 85);
scores.put("Anita", 88);
// Iterate over entrySet
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// Iterate over keys
for (String key : scores.keySet()) {
System.out.println("Key: " + key);
}
// Iterate over values
for (Integer value : scores.values()) {
System.out.println("Value: " + value);
}class를 여러개 상속 받을 수 없는 비슷한 이유
이것과 비슷한 개념으로 class의 상속이 존재하는데요
class는 기본적으로 상태를 가지게 됩니다.
상태를 가진다는 것은 Field 값이 존재한다는 것이고, method 를 통해 이를 조작하게 됩니다.
재밌는 상상을 해볼까요?
만약 dragon, bird 두 개의 클래스를 상속받는다 가정하고
각각이 fly() 라는 메서드와 ,wings 라는 필드가 존재한다고 하겠습니다.
class Bird{
int wings;
public void fly(){
// do something
}
}
class Dragon{
int wings;
public void fly(){
// do something
}
}
class bat extends Dragon, Bird{
// 누구의 날개를 사용해서 어떻게 날 것인가?
// error
}이를 상속받은 클래스에서는 과연 누구의 wings를 가지고 어떻게 fly() 연산을 수행해야 할까요?
이렇게 직접적인 구현을 가지고 있는 클래스는 여러개를 상속받게 하는 순간 모호함에서 오는 이상이 발생할 수 있기 때문에
자바에서는 원칙적으로 막아두는 것 입니다.
반면에 interface는 상태를 가지지않고, 그저 어떤 연산이 가능한지만 명시해놓는 명세서입니다.
따라서 여러개를 상속받아도 모호함에서 오는 이상이 없는 것 이죠
그렇기 때문에 interface의 경우는 여러개를 상속받는 것을 막아두지 않습니다.
'Article' 카테고리의 다른 글
| [Medium] 초보처럼 if-else 쓰지 않는 법 (0) | 2025.09.07 |
|---|---|
| [Medium] 동기·비동기, IO·NIO, 그리고 Virtual Thread (1) | 2025.09.01 |
| [Medium] 왜 자바 Stream은 대규모 환경에 적합하지 않은가? (1) | 2025.08.29 |
| [Medium] 메서드 시그니처에 List 대신 Collection/Iterable을 고려해야 하는 이유 (1) | 2025.08.29 |
| [Medium] 자바를 2025년 처럼 사용하는 법 (1) (0) | 2025.08.29 |













