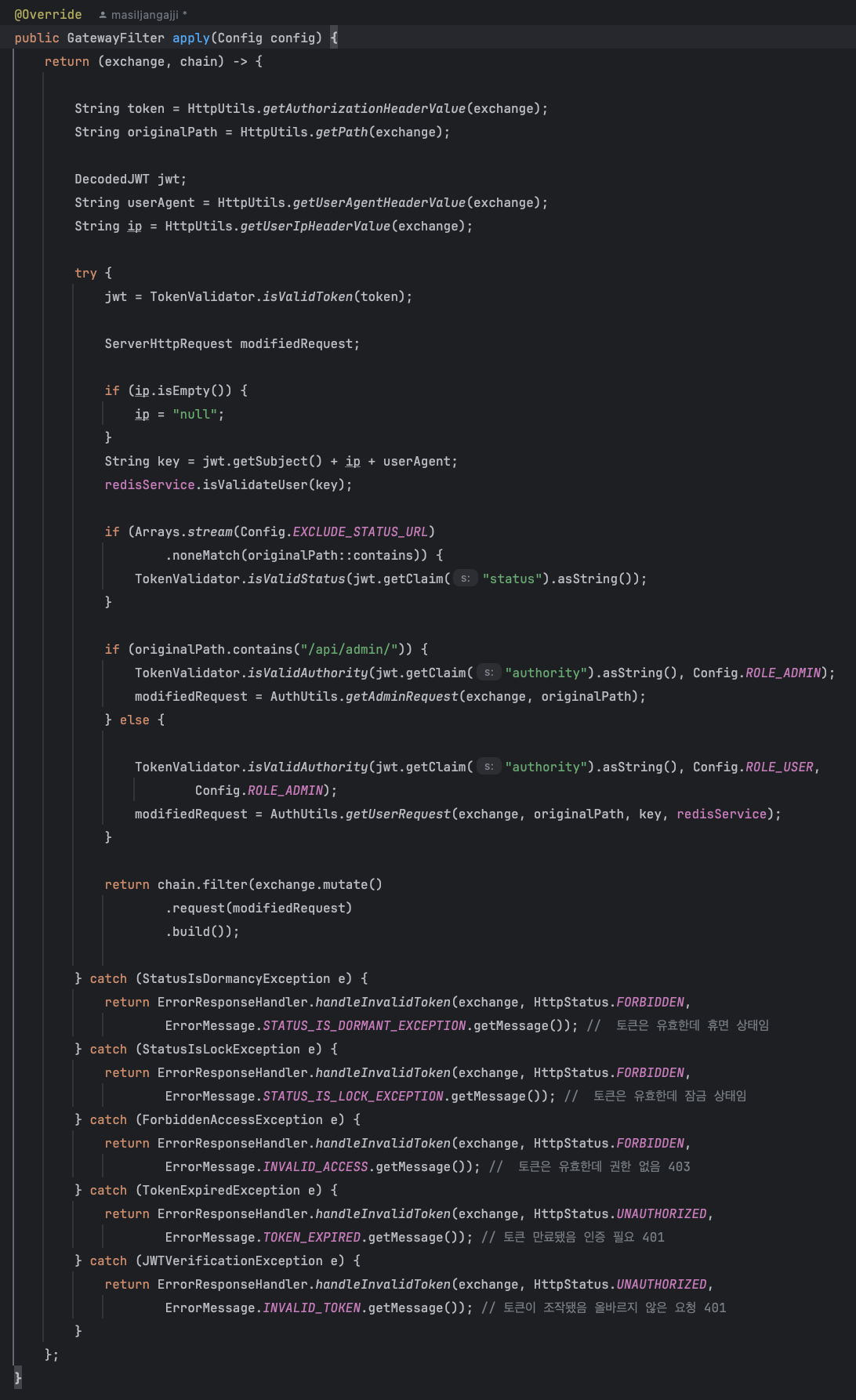
GPT 요약
My-Music-Note 프로젝트에서 SonarCloud와 GitHub Actions 같은 SaaS 도구를 활용해 서비스 비용을 절감했습니다.
Bastion Host 대신 AWS Systems Manager를 도입해 보안을 강화하고 네트워크 비용을 줄였습니다.
이러한 선택으로 비용 효율성과 운영 효율성을 모두 확보할 수 있었습니다.My-Music-Note 프로젝트에서의 경험을 다룬 글입니다.
이전 프로젝트들은 교육기관이나 회사에서 제공한 환경에서 진행되었기 때문에 서버 비용 같은 것은 크게 신경 쓰지 않았습니다.
그러나 이번 프로젝트는 직접적으로 돈이 나가는 상황이었기 때문에 자연스럽게 비용을 줄이면서도 효율성을 높이는 방법에 대해 고민하게 되었습니다.
서비스 비용 절감 - SonarCloud와 GitHub Actions 선택
My-Music-Note 이전에 진행했던 My-Books 프로젝트에서는 SonarQube로 코드 품질을 관리하고 CI/CD 도구로는 Jenkins를 사용했습니다.
My-Books는 NHN Academy에서 진행한 것으로 인프라 관리비용을 NHN측에서 전액 부담해주었기 때문에 비용 고민이 없었습니다.
하지만 이번 프로젝트는 제 돈으로 운영해야 했기 때문에 별도의 서버 관리가 필요하지 않은 도구를 찾아야 했으며
결과적으로 SonarCloud와 GitHub Actions라는 SaaS 기반 도구를 선택하게 되었습니다.
SonarCloud - SaaS형 코드 품질 관리 도구
SonarCloud는 SaaS(Software as a Service)로 제공되며 SonarQube처럼 별도의 서버를 설치하거나 관리할 필요가 없습니다.GitHub 공개 저장소에 한해서 전체 기능을 무료로 제공받을 수 있어 규모가 작은 스타트업이나 팀 프로젝트의 경우에는 매우 적합하다 생각합니다.
물론 SonarQube에 비해 부족한 부분도 존재합니다.
- 제한된 언어 지원 언어지원과(C,Objective-C,PL/SQL...)
- 타사 플러그인의 부재
- 모노레포등 복잡한 프로젝트 구조에 대한 지원 부족
다행히 My-Music-Note 서비스는는 이러한 제약 조건과 관련이 적었기 때문에 SonarCloud를 사용하는 데 만족했습니다.
GitHub Actions - 클라우드 기반 CI/CD
GitHub Actions도 SaaS로 제공되며 SonarCloud와 동일하게 GitHub 공개 저장소에 한해서 무료로 사용할 수 있습니다.
Jenkins와 달리 서버 비용이 필요하지 않으며 GitHub Actions Marketplace 활용시 AWS, Google Cloud , Docker 등 다양한 Actions를 쉽게 추가하여 CI/CD 파이프라인을 확장할 수 있습니다.

개인적으로는 이 부분이 매우 강력하다고 느꼈으며 Jenkins와 비교해도 기능이 제한적일 것 같다는 생각은 들지 않았습니다.
특히나 국내 빅테크에서도 GitHub Actions를 사용하는 사례가 있는만큼 대규모 조직에서도 충분히 활용 가능해보입니다.
네트워크 비용 절감 - Bastion Host에서 Systems Manager로 전환
AWS 기반 인프라에서는 프라이빗 서브넷의 EC2 인스턴스에 접근하는 방법 또한 비용 절감 요소중 하나 입니다.
기존에는 Bastion Host를 사용했지만 이 방식에는 몇 가지 한계가 있었습니다.
Bastion Host - 작동 방식과 한계
Bastion Host는 퍼블릭 서브넷에 배치된 EC2 인스턴스로 외부에서 접근 가능한 경로를 제공합니다.
이를 통해 프라이빗 서브넷의 EC2 인스턴스에 접근할 수 있지만 다음과 같은 문제점이 발생합니다.
- 보안 취약점:
- Bastion Host는 외부 인터넷에 노출되어 보안 위협이 존재
- PEM 키 관리의 복잡성:
- 여러 프라이빗 인스턴스의 PEM 키를 Bastion Host에 복사하고 관리해야 함
- 추가 비용 발생:
- Bastion Host 자체가 EC2 인스턴스이기 때문에 유지비용이 발생

Systems Manager - 더 안전하고 효율적인 네트워크 접근 방식
이러한 문제를 해결하기 위해 AWS Systems Manager를 도입했습니다.
Systems Manager는 AWS 내부 네트워크를 활용하기 때문에 인터넷 연결 없이도 EC2 인스턴스에 안전하게 접근할 수 있으며
PEM 키를 관리하지 않아도 되는 편리함 , Bastion Host와 같은 EC2 인스턴스를 유지할 필요가 없어 비용이 절감되는 등 다양한 장점이 존재합니다.
실제로 사용해보니 일반적인 터미널 환경과 유사했으며 기존 Bastion Host 방식보다 간편하고 효율적이였습니다.

My-Music-Note 프로젝트에서 SaaS 기반 도구(SonarCloud, GitHub Actions)와 Systems Manager를 도입한 결과 서비스 비용과 네트워크 비용을 모두 절감할 수 있었습니다.
같이 보시면 좋은 발표 영상입니다.
'프로젝트 > My-Music-Note' 카테고리의 다른 글
| Artillery를 활용한 테스트, 이렇게 도입했습니다 (1) | 2025.01.10 |
|---|---|
| AWS 인프라 트러블슈팅 - 배포 전략과 컨테이너 전환 (2) | 2025.01.09 |